
2024
hi
L’Orsa, R., Bisht, A., Yu, L., Murari, K., Westwick, D. T., Sutherland, G. R., Kuchenbecker, K. J.
Reflectance Outperforms Force and Position in Model-Free Needle Puncture Detection
In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, USA, July 2024 (inproceedings) Accepted

ps
Fan, Z., Parelli, M., Kadoglou, M. E., Kocabas, M., Chen, X., Black, M. J., Hilliges, O.
HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video
Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2024 (conference) Accepted
ei
Gao, G., Liu, W., Chen, A., Geiger, A., Schölkopf, B.
GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs
The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024 (conference) Accepted

ps
Chhatre, K., Daněček, R., Athanasiou, N., Becherini, G., Peters, C., Black, M. J., Bolkart, T.
AMUSE: Emotional Speech-driven 3D Body Animation via Disentangled Latent Diffusion
Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2024 (conference) To be published
ei
Guo, S., Wildberger, J., Schölkopf, B.
Out-of-Variable Generalization for Discriminative Models
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024 (conference) Accepted
ei
Pace, A., Yèche, H., Schölkopf, B., Rätsch, G., Tennenholtz, G.
Delphic Offline Reinforcement Learning under Nonidentifiable Hidden Confounding
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024 (conference) Accepted
ei
Meterez*, A., Joudaki*, A., Orabona, F., Immer, A., Rätsch, G., Daneshmand, H.
Towards Training Without Depth Limits: Batch Normalization Without Gradient Explosion
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024, *equal contribution (conference) Accepted
hi
Rokhmanova, N., Martus, J., Faulkner, R., Fiene, J., Kuchenbecker, K. J.
GaitGuide: A Wearable Device for Vibrotactile Motion Guidance
Workshop paper (3 pages) presented at the ICRA Workshop on Advancing Wearable Devices and Applications Through Novel Design, Sensing, Actuation, and AI, Yokohama, Japan, May 2024 (misc) Accepted
ei
al
Spieler, A., Rahaman, N., Martius, G., Schölkopf, B., Levina, A.
The Expressive Leaky Memory Neuron: an Efficient and Expressive Phenomenological Neuron Model Can Solve Long-Horizon Tasks
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024 (conference) Accepted
ei
Open X-Embodiment Collaboration ( incl. Guist, S., Schneider, J., Schölkopf, B., Büchler, D. ).
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
IEEE International Conference on Robotics and Automation (ICRA), May 2024 (conference) Accepted
ei
Jin, Z., Liu, J., Lyu, Z., Poff, S., Sachan, M., Mihalcea, R., Diab*, M., Schölkopf*, B.
Can Large Language Models Infer Causation from Correlation?
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024, *equal supervision (conference) Accepted
ei
Donhauser, K., Lokna, J., Sanyal, A., Boedihardjo, M., Hönig, R., Yang, F.
Certified private data release for sparse Lipschitz functions
27th International Conference on Artificial Intelligence and Statistics (AISTATS), May 2024 (conference) Accepted
ei
ps
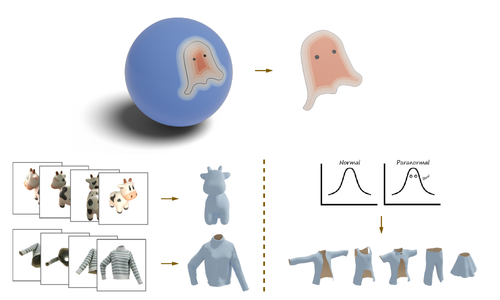
Liu, Z., Feng, Y., Xiu, Y., Liu, W., Paull, L., Black, M. J., Schölkopf, B.
Ghost on the Shell: An Expressive Representation of General 3D Shapes
In Proceedings of the Twelfth International Conference on Learning Representations, The Twelfth International Conference on Learning Representations, May 2024 (inproceedings) Accepted
ei
Schneider, J., Schumacher, P., Guist, S., Chen, L., Häufle, D., Schölkopf, B., Büchler, D.
Identifying Policy Gradient Subspaces
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024 (conference) Accepted
al
Khajehabdollahi, S., Zeraati, R., Giannakakis, E., Schäfer, T. J., Martius, G., Levina, A.
Emergent mechanisms for long timescales depend on training curriculum and affect performance in memory tasks
In The Twelfth International Conference on Learning Representations, ICLR 2024, May 2024 (inproceedings)
ei
Khromov*, G., Singh*, S. P.
Some Intriguing Aspects about Lipschitz Continuity of Neural Networks
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024, *equal contribution (conference) Accepted
ei
ps
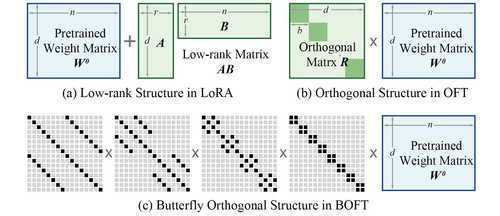
Liu, W., Qiu, Z., Feng, Y., Xiu, Y., Xue, Y., Yu, L., Feng, H., Liu, Z., Heo, J., Peng, S., Wen, Y., Black, M. J., Weller, A., Schölkopf, B.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
In Proceedings of the Twelfth International Conference on Learning Representations, The Twelfth International Conference on Learning Representations, May 2024 (inproceedings) Accepted
ei
Pan, H., Schölkopf, B.
Skill or Luck? Return Decomposition via Advantage Functions
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024 (conference) Accepted
ei
Imfeld*, M., Graldi*, J., Giordano*, M., Hofmann, T., Anagnostidis, S., Singh, S. P.
Transformer Fusion with Optimal Transport
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024, *equal contribution (conference) Accepted
al
Gumbsch, C., Sajid, N., Martius, G., Butz, M. V.
Learning Hierarchical World Models with Adaptive Temporal Abstractions from Discrete Latent Dynamics
In The Twelfth International Conference on Learning Representations, ICLR 2024, May 2024 (inproceedings)
ei
Lorch, L., Krause*, A., Schölkopf*, B.
Causal Modeling with Stationary Diffusions
27th International Conference on Artificial Intelligence and Statistics (AISTATS), May 2024, *equal supervision (conference) Accepted
ei
al
Yao, D., Xu, D., Lachapelle, S., Magliacane, S., Taslakian, P., Martius, G., von Kügelgen, J., Locatello, F.
Multi-View Causal Representation Learning with Partial Observability
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024 (conference) Accepted
ei
Theus, A., Geimer, O., Wicke, F., Hofmann, T., Anagnostidis, S., Singh, S. P.
Towards Meta-Pruning via Optimal Transport
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024 (conference) Accepted
ei
Lin*, J. A., Padhy*, S., Antorán*, J., Tripp, A., Terenin, A., Szepesvari, C., Hernández-Lobato, J. M., Janz, D.
Stochastic Gradient Descent for Gaussian Processes Done Right
Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024, *equal contribution (conference) Accepted

hi
Javot, B., Nguyen, V. H., Ballardini, G., Kuchenbecker, K. J.
CAPT Motor: A Strong Direct-Drive Rotary Haptic Interface
Hands-on demonstration presented at the IEEE Haptics Symposium, Long Beach, USA, April 2024 (misc)
hi
rm
Sanchez-Tamayo, N., Yoder, Z., Ballardini, G., Rothemund, P., Keplinger, C., Kuchenbecker, K. J.
Cutaneous Electrohydraulic (CUTE) Wearable Devices for Multimodal Haptic Feedback
Extended abstract (1 page) presented at the IEEE RoboSoft Workshop on Multimodal Soft Robots for Multifunctional Manipulation, Locomotion, and Human-Machine Interaction, San Diego, USA, April 2024 (misc)
hi
Fazlollahi, F., Seifi, H., Ballardini, G., Taghizadeh, Z., Schulz, A., MacLean, K. E., Kuchenbecker, K. J.
Quantifying Haptic Quality: External Measurements Match Expert Assessments of Stiffness Rendering Across Devices
Work-in-progress paper (2 pages) presented at the IEEE Haptics Symposium, Long Beach, USA, April 2024 (misc)
hi
rm
Sanchez-Tamayo, N., Yoder, Z., Ballardini, G., Rothemund, P., Keplinger, C., Kuchenbecker, K. J.
Cutaneous Electrohydraulic Wearable Devices for Expressive and Salient Haptic Feedback
Hands-on demonstration presented at the IEEE Haptics Symposium, Long Beach, USA, April 2024 (misc)
ei
Hu, Y., Pinto, F., Yang, F., Sanyal, A.
PILLAR: How to make semi-private learning more effective
2nd IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), April 2024 (conference) Accepted

hi
Serhat, G., Kuchenbecker, K. J.
Fingertip Dynamic Response Simulated Across Excitation Points and Frequencies
Biomechanics and Modeling in Mechanobiology, April 2024 (article) Accepted
hi
rm
Sanchez-Tamayo, N., Yoder, Z., Ballardini, G., Rothemund, P., Keplinger, C., Kuchenbecker, K. J.
Demonstration: Cutaneous Electrohydraulic (CUTE) Wearable Devices for Expressive and Salient Haptic Feedback
Hands-on demonstration presented at the IEEE RoboSoft Conference, San Diego, USA, April 2024 (misc)
hi
Mohan, M., Mat Husin, H., Kuchenbecker, K. J.
Expert Perception of Teleoperated Social Exercise Robots
In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages: 769-773, Boulder, USA, March 2024, Late-Breaking Report (LBR) (5 pages) presented at the IEEE/ACM International Conference on Human-Robot Interaction (HRI) (inproceedings)

ps
Liao, T., Yi, H., Xiu, Y., Tang, J., Huang, Y., Thies, J., Black, M. J.
TADA! Text to Animatable Digital Avatars
In International Conference on 3D Vision (3DV 2024), 3DV 2024, March 2024 (inproceedings) Accepted

ps
Dwivedi, S. K., Schmid, C., Yi, H., Black, M. J., Tzionas, D.
POCO: 3D Pose and Shape Estimation using Confidence
In International Conference on 3D Vision (3DV 2024), 3DV 2024, March 2024 (inproceedings)

ncs
ps
Zhang, H., Feng, Y., Kulits, P., Wen, Y., Thies, J., Black, M. J.
TECA: Text-Guided Generation and Editing of Compositional 3D Avatars
In International Conference on 3D Vision (3DV 2024), 3DV 2024, March 2024 (inproceedings) To be published
ncs
Kabadayi, B., Zielonka, W., Bhatnagar, B. L., Pons-Moll, G., Thies, J.
GAN-Avatar: Controllable Personalized GAN-based Human Head Avatar
In International Conference on 3D Vision (3DV), March 2024 (inproceedings)
ps
Huang, Y., Yi, H., Xiu, Y., Liao, T., Tang, J., Cai, D., Thies, J.
TeCH: Text-guided Reconstruction of Lifelike Clothed Humans
In International Conference on 3D Vision (3DV 2024), 3DV 2024, March 2024 (inproceedings) Accepted

ps
Zhang, H., Christen, S., Fan, Z., Zheng, L., Hwangbo, J., Song, J., Hilliges, O.
ArtiGrasp: Physically Plausible Synthesis of Bi-Manual Dexterous Grasping and Articulation
In International Conference on 3D Vision (3DV 2024), 3DV 2024, March 2024 (inproceedings) Accepted
ei
von Kügelgen, J.
Identifiable Causal Representation Learning
University of Cambridge, UK, Cambridge, February 2024, (Cambridge-Tübingen-Fellowship) (phdthesis)
hi
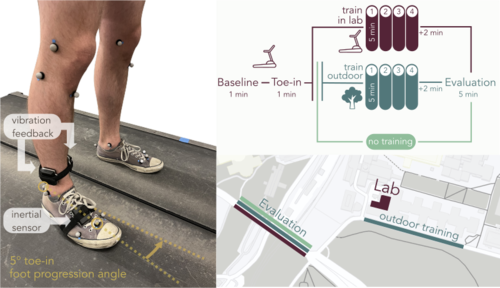
Rokhmanova, N., Pearl, O., Kuchenbecker, K. J., Halilaj, E.
IMU-Based Kinematics Estimation Accuracy Affects Gait Retraining Using Vibrotactile Cues
IEEE Transactions on Neural Systems and Rehabilitation Engineering, 32, pages: 1005-1012, February 2024 (article)
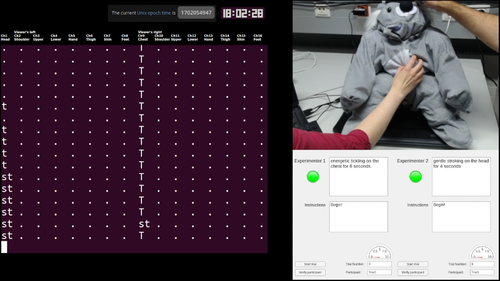
hi
Burns, R.
Creating a Haptic Empathetic Robot Animal That Feels Touch and Emotion
University of Tübingen, Tübingen, Germany, February 2024, Department of Computer Science (phdthesis)

hi
Schulz, A., Serhat, G., Kuchenbecker, K. J.
Adapting a High-Fidelity Simulation of Human Skin for Comparative Touch Sensing in the Elephant Trunk
Abstract presented at the Society for Integrative and Comparative Biology Annual Meeting (SICB), Seattle, USA, January 2024 (misc)

ps
Ben-Dov, O., Gupta, P. S., Abrevaya, V., Black, M. J., Ghosh, P.
Adversarial Likelihood Estimation With One-Way Flows
In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages: 3779-3788, January 2024 (inproceedings)
ei
OS Lab
Kottapalli, S. N. M., Schlieder, L., Song, A., Volchkov, V., Schölkopf, B., Fischer, P.
Polarization-based non-linear deep diffractive neural networks
AI and Optical Data Sciences V, PC12903, pages: PC129030B, (Editors: Ken-ichi Kitayama and Volker J. Sorger), SPIE, January 2024 (conference)
ei
Song, A., Kottapalli, S. N. M., Schölkopf, B., Fischer, P.
Multi-channel free space optical convolutions with incoherent light
AI and Optical Data Sciences V, PC12903, pages: PC129030I, (Editors: Ken-ichi Kitayama and Volker J. Sorger), SPIE, January 2024 (conference)
hi
Khojasteh, B., Shao, Y., Kuchenbecker, K. J.
MPI-10: Haptic-Auditory Measurements from Tool-Surface Interactions
Dataset published as a companion to the journal article "Robust Surface Recognition with the Maximum Mean Discrepancy: Degrading Haptic-Auditory Signals through Bandwidth and Noise" in IEEE Transactions on Haptics, January 2024 (misc)
hi
Fitter, N. T., Mohan, M., Preston, R. C., Johnson, M. J., Kuchenbecker, K. J.
How Should Robots Exercise with People? Robot-Mediated Exergames Win with Music, Social Analogues, and Gameplay Clarity
Frontiers in Robotics and AI, 10(1155837):1-18, January 2024 (article)

zwe-csfm
hi
Schulz, A., Kaufmann, L., Brecht, M., Richter, G., Kuchenbecker, K. J.
Whiskers That Don’t Whisk: Unique Structure From the Absence of Actuation in Elephant Whiskers
Abstract presented at the Society for Integrative and Comparative Biology Annual Meeting (SICB), Seattle, USA, January 2024 (misc)
hi
Khojasteh, B., Shao, Y., Kuchenbecker, K. J.
Robust Surface Recognition with the Maximum Mean Discrepancy: Degrading Haptic-Auditory Signals through Bandwidth and Noise
IEEE Transactions on Haptics, 17(1):58-65, January 2024, Presented at the IEEE Haptics Symposium (article)
ev
Kandukuri, R. K., Strecke, M., Stueckler, J.
Physics-Based Rigid Body Object Tracking and Friction Filtering From RGB-D Videos
In International Conference on 3D Vision (3DV), 2024, accepted, preprint arXiv: 2309.15703 (inproceedings) Accepted